|
Inbar Mosseri I'm a Principal Research Scientist (Director) leading a research group at Google DeepMind in Tel-Aviv, focusing on image and video creation and editing using generative models. At the heart of my work is a deep passion for the intersection of AI and visual arts, where I'm constantly pushing the boundaries to explore how these cutting-edge technologies can revolutionize both academic research and the development of new product capabilities. |

|
Research & Product Highlights |
|

|

|

|

|
|

|

|
|

|
|

|
PublicationsI'm interested in computer vision, deep learning, generative AI, and image processing. Most of my recent research work focuses on generative models for image and video. Representative papers are highlighted. |

|
Daniel Garibi, Shahar Yadin, Roni Paiss, Omer Tov, Shiran Zada, Ariel Efrat, Tomer Michaeli, Inbar Mosseri, Tali Dekel, Best Paper Award, SIGGRAPH, 2025 Project |

|
David Junhao Zhang, Roni Paiss, Shiran Zada, Nikhil Karnad, Yael Pritch, Inbar Mosseri, Mike Z. SHOU, Neal Wadhwa, Nataniel Ruiz, CVPR, 2025 Project |

|
Hila Chefer, Shiran Zada, Roni Paiss, Ariel Efrat, Omer Tov, Michael Rubinstein, Lior Wolf, Tali Dekel, Tomer Michaeli, Inbar Mosseri SIGGRAPH Asia (Journal), 2024 Project |

|
Omer Bartal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Efrat, Junhwa Hur , Yuanzhen Li Tomer Michaeli, Oliver Wang, Deqing Sun, Tali Dekel, Inbar Mosseri SIGGRAPH Asia, 2024 Project |
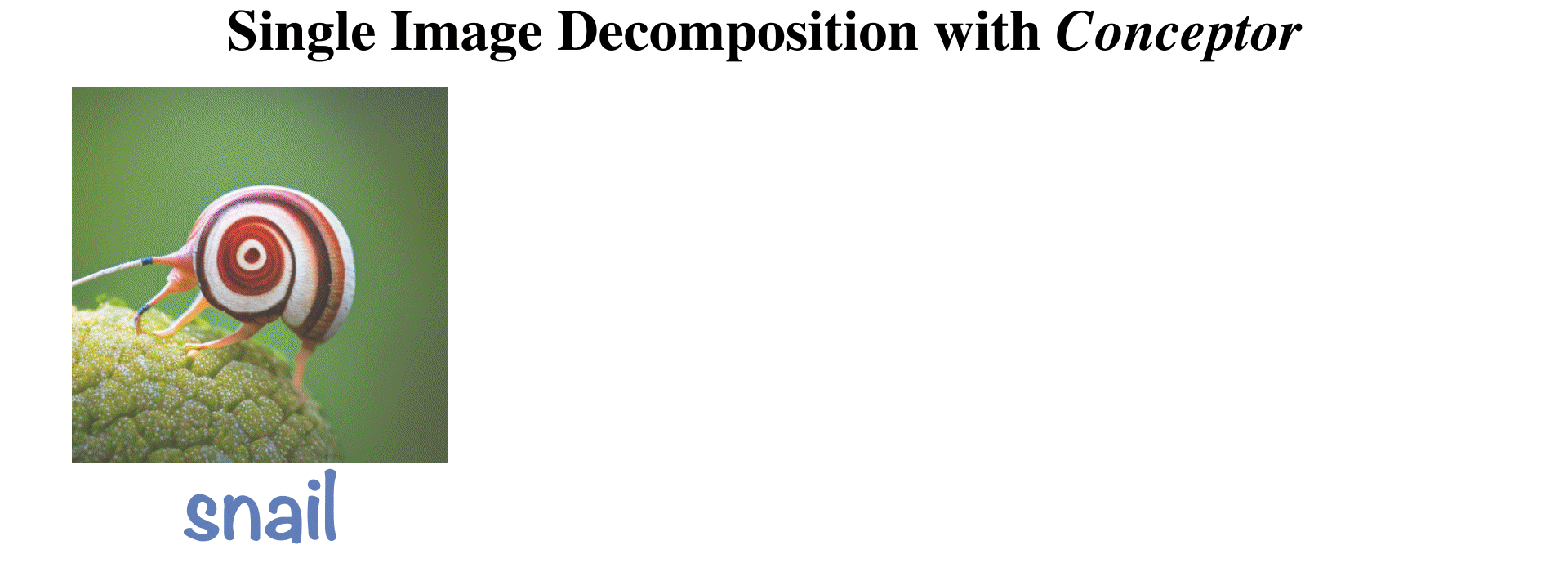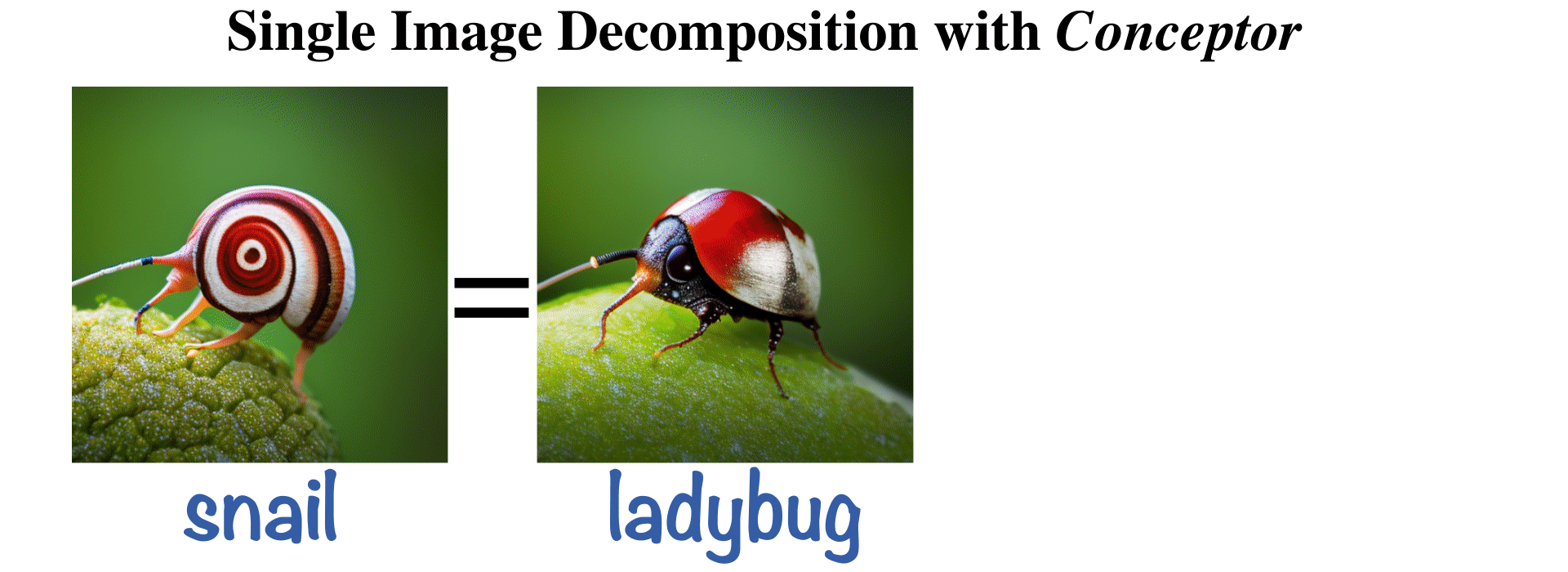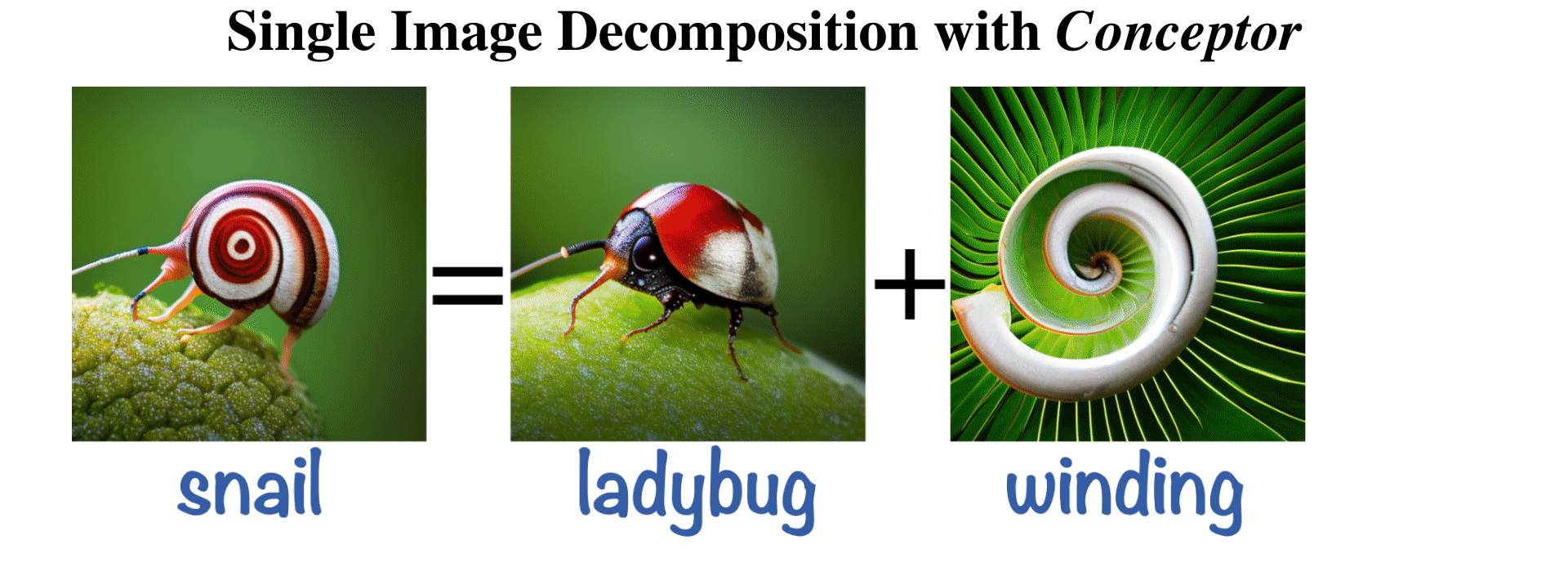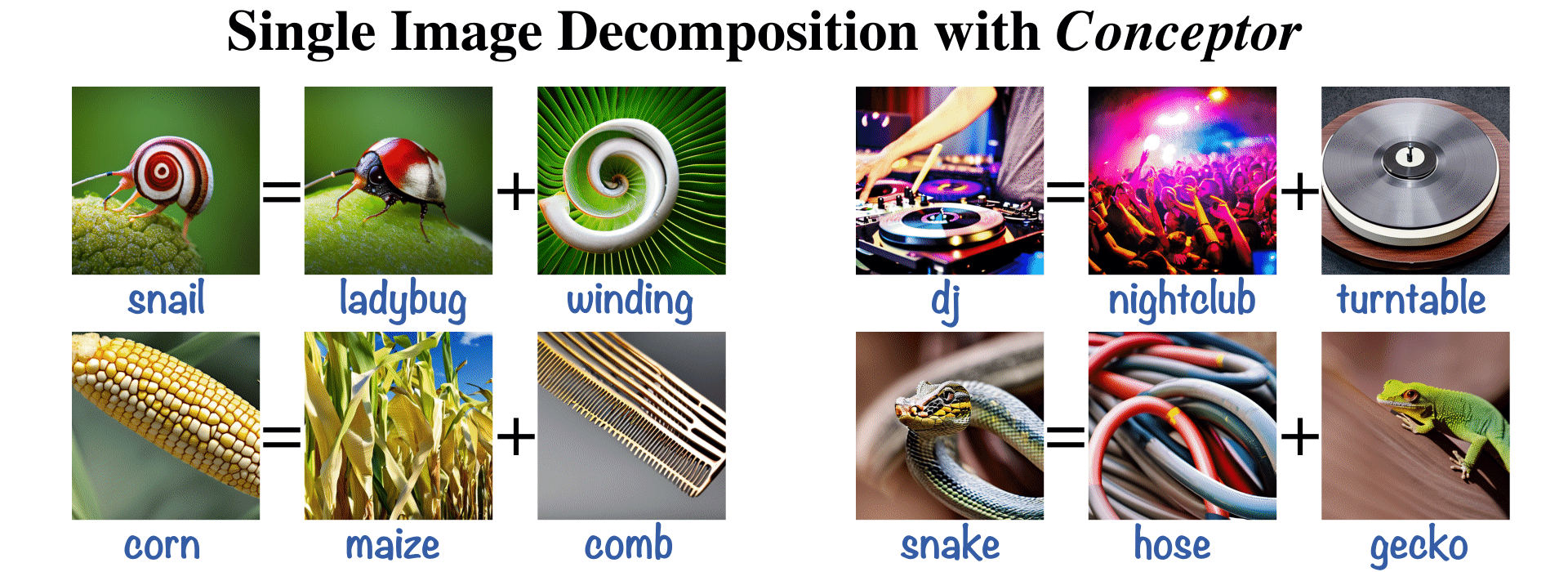
|
Hila Chefer, Oran Lang, Mor Geva, Volodymyr Polosukhin, Assaf Shocher, Michal Irani, Inbar Mosseri, Lior Wolf ICLR, 2024 Paper / Project |

|
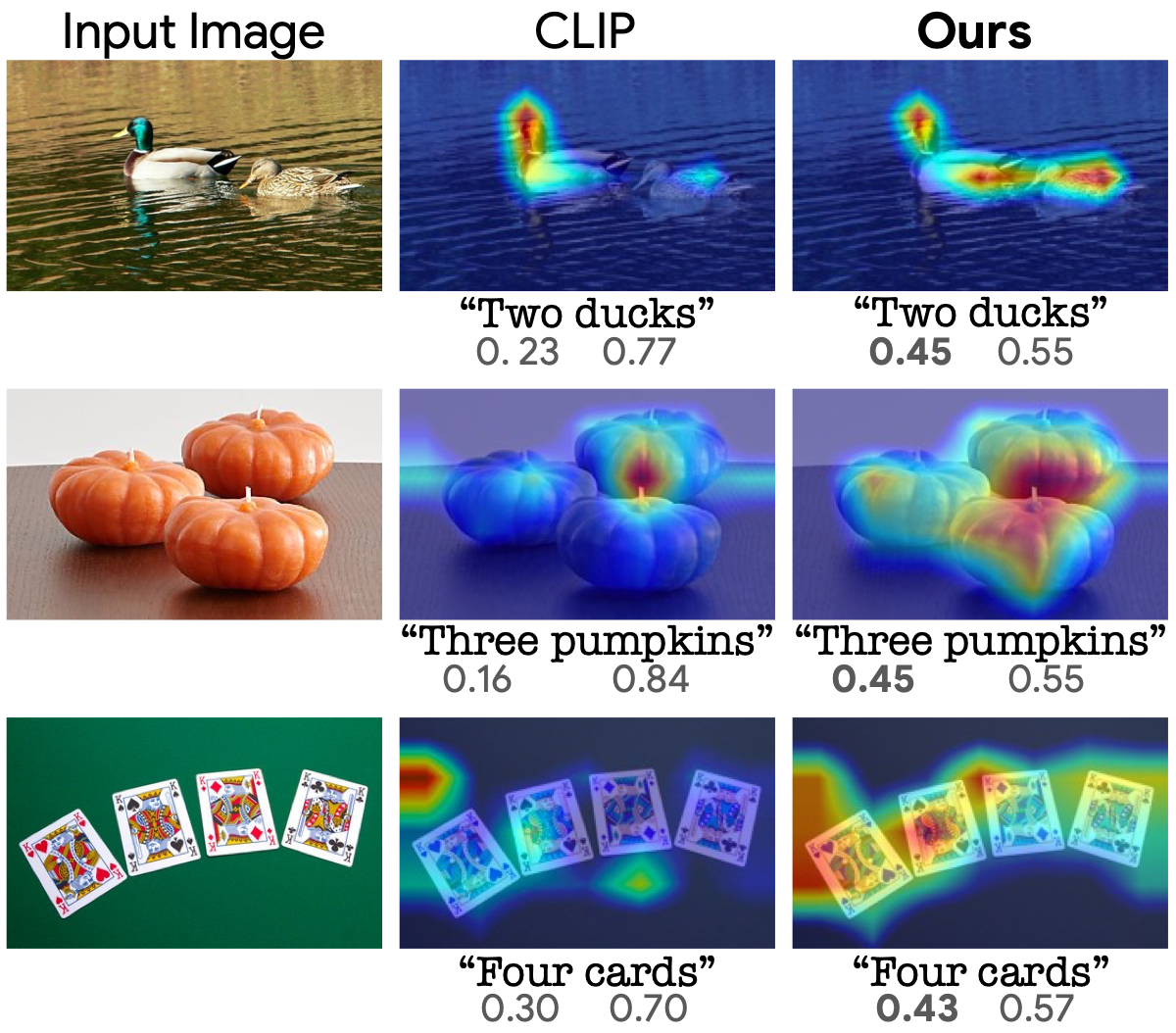
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, Michal Irani CVPR, 2023 Paper / Project |
|
Roni Paiss, Ariel Efrat, Omer Tov, Shiran Zada, Inbar Mosseri, Michal Irani, Tali Dekel, ICCV, 2023 Paper / Project |

|
Yotam Nitzan, Kfir Aberman, Qiurui He, Michal Yarom, Yossi Gandelsman, Inbar Mosseri, Yael Pritch Daniel Cohen-or SIGGRAPH Asia, 2022 Paper / Project / Video |

|
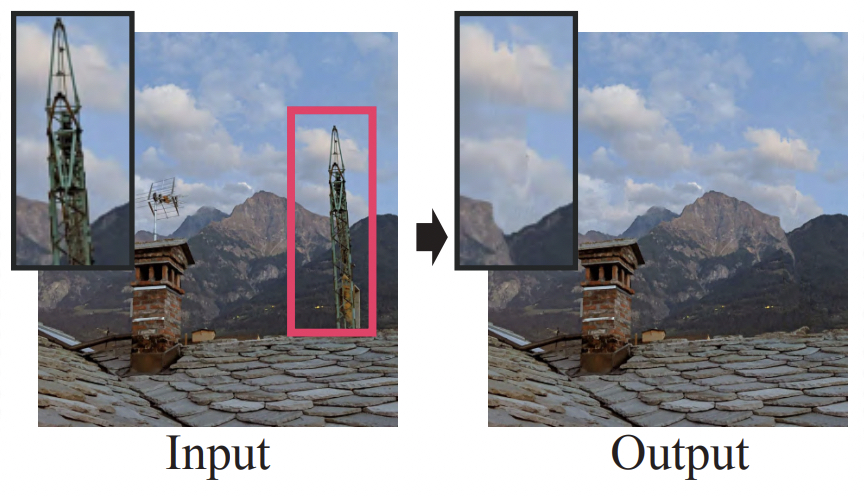
Ron Mokady, Michal Yarom, Omer Tov, Oran Lang, Daniel Cohen-or Michal Irani, Inbar Mosseri SIGGRAPH, 2022 Paper / Project |
|
Kfir Aberman, Junfeng He, Yossi Gandelsman, Inbar Mosseri, David E. Jacobs, Kai Kohlhoff, Yael Pritch, Michael Rubinstein CVPR, 2022 Paper / Project |

|
Oran Lang, Yossi Gandelsman, Michal Yarom, Yoav Wald, Gal Elidan, Avinatan Hassidim, William T. Freeman, Phillip Isola, Amir Globerson, Michal Irani, Inbar Mosseri CVPR, 2021 Paper / Project / Blog Post |
|
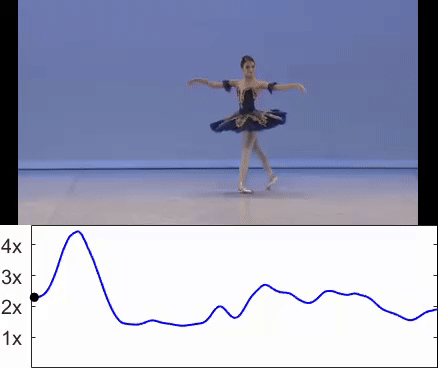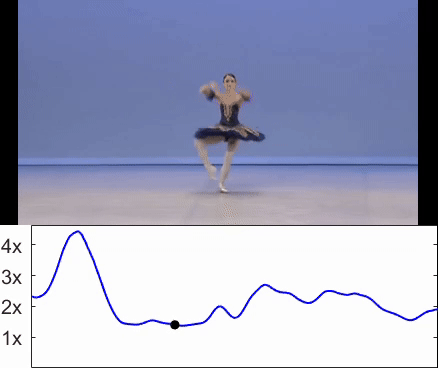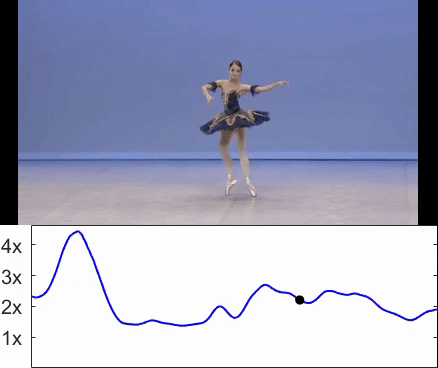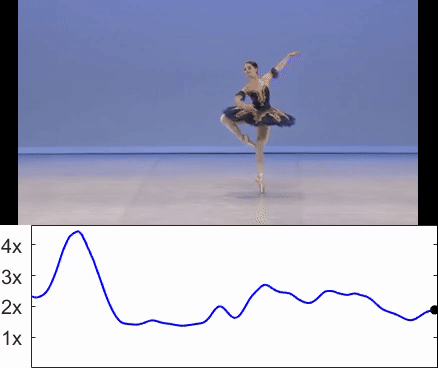
Sagie Benaim, Ariel Efrat, Oran Lang, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Michal Irani, Tali Dekel CVPR, 2020 Paper / Project |
|
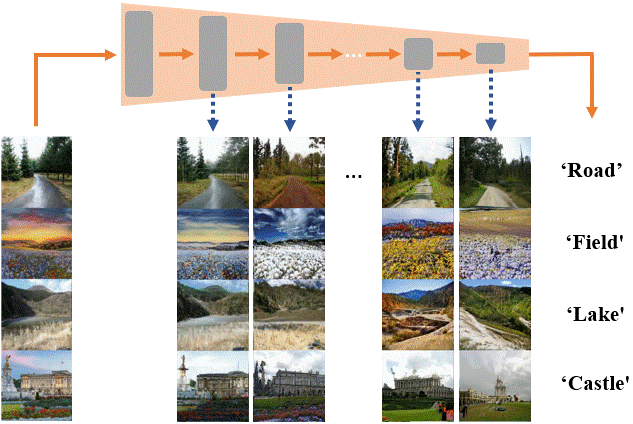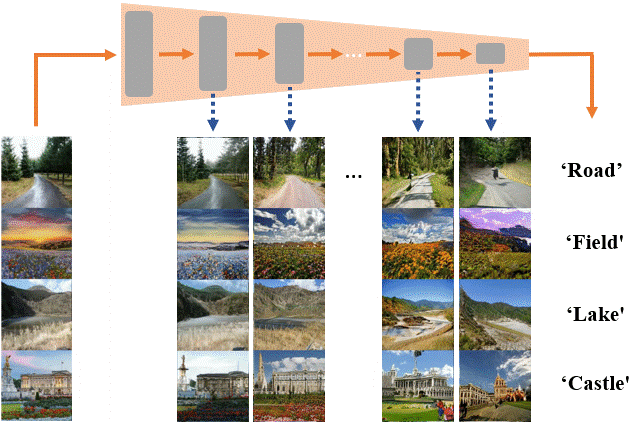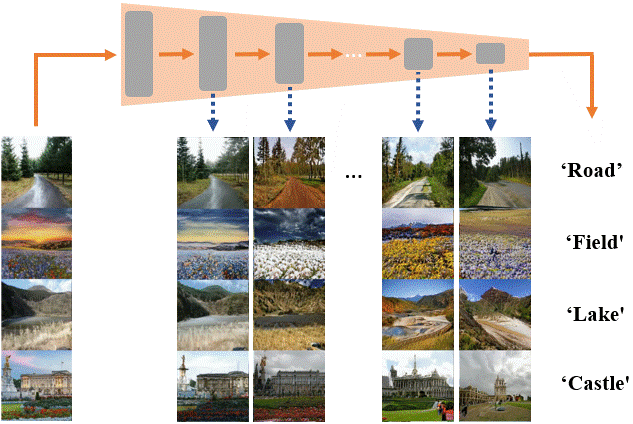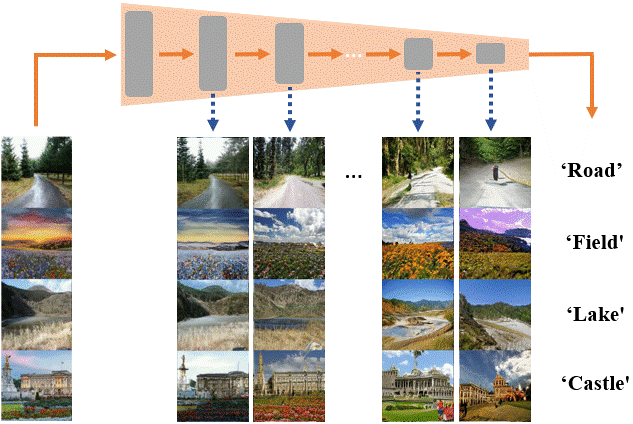
Assaf Shocher, Yossi Gandelsman, Inbar Mosseri, Michal Yarom, Michal Irani, William T. Freeman, Tali Dekel CVPR, 2020 Paper / Project |

|
Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Wojciech Matusik, CVPR, 2019 Paper / Project |

|
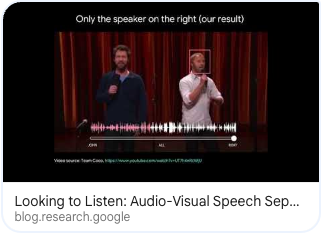
Ariel Efrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, Michael Rubinstein SIGGRAPH, 2018 Paper / Project |
|
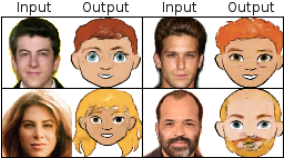
Amelie Royer, Konstantinos Bousmalis, Stephan Gouws, Fred Bertsch, Inbar Mosseri, Forrester Cole, Kevin Murphy ICLR, 2018 Paper |

|
Forrester Cole, David Belanger, Dilip Krishnan, Aaron Sarna Inbar Mosseri, William T. Freeman, CVPR, 2017 Paper |
|
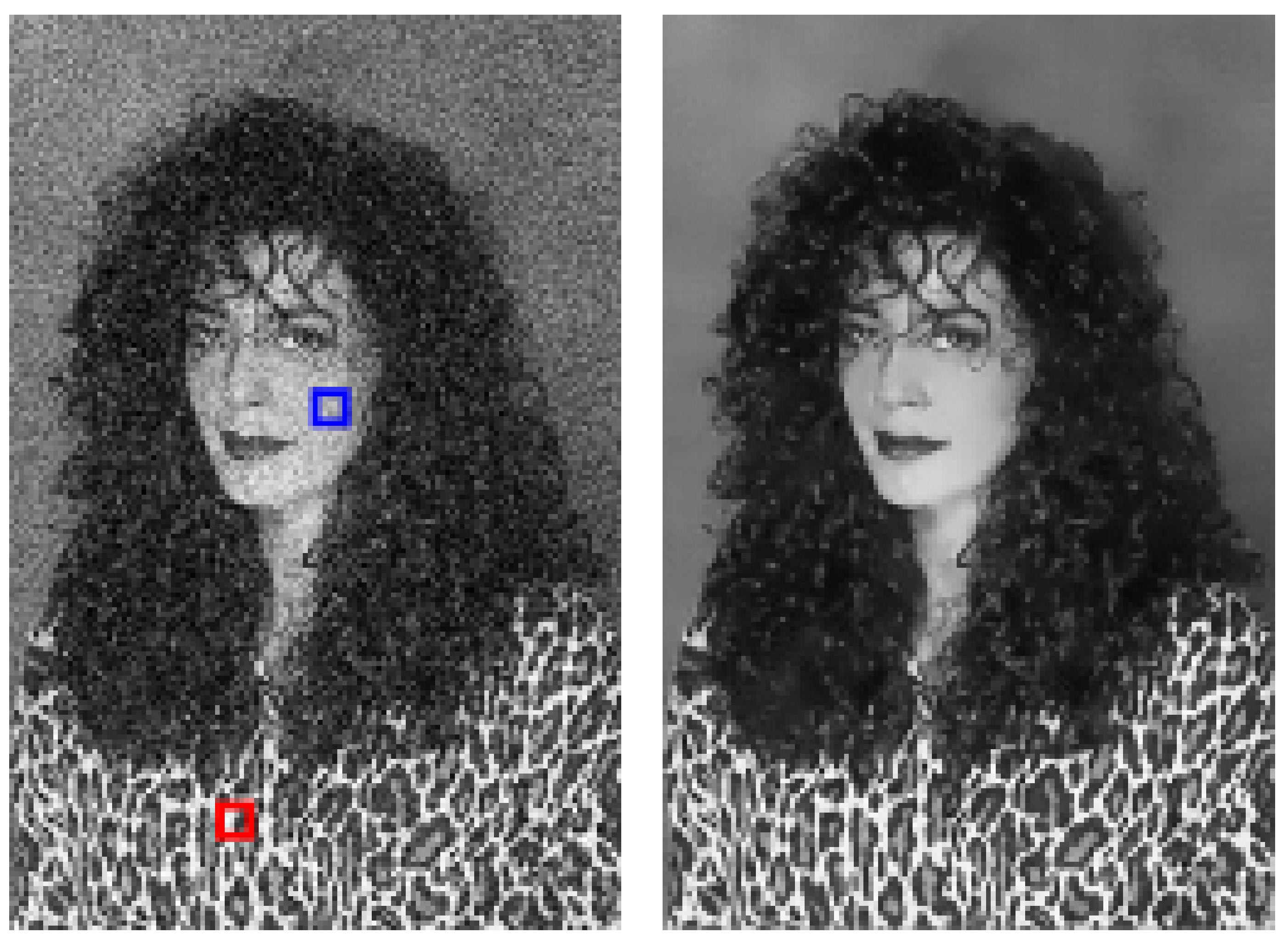
Inbar Mosseri, Maria Zontak, Michal Irani ICCP, 2013 Paper |
|
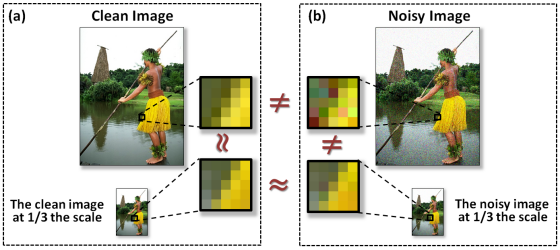
Maria Zontak, Inbar Mosseri, Michal Irani CVPR, 2013 Paper / Project |
|
|